图像语义分割基础-FCN
阅读时长:2 min
语义分割是机器视觉的一个分支,不同于目标识别,它不需要将每个对象检测出来,而是对图像中每一个像素点进行分类,确定每个点的类别,从而进行区域划分。Fully Convolutional Networks(FCN)是语义分割的基本框架,这篇文章来分析FCN的基本架构和原理,从而入门语义分割领域。

FCN做了什么
我们知道图像分类是对整幅图进行分类,而语义分割是实际上是对每个像素点进行分类。由于CNN在卷积和池化的过程中特征图会逐渐减小,对于具体物品来说,就很难找到它的轮廓,难以指出每个像素点属于哪个物品。因此就难以进行精确分割。并且传统分类框架,如VGG、RESNET等网络,他们的Head都是一些全连接层+softmax的形式,直接得到类别的概率信息,这些信息是1维的,并不能实现对所有像素的分类,因此不能用作语义分割。而FCN将后面的全连接层全都换成了卷积,这样就可以实现对每个像素的分类。
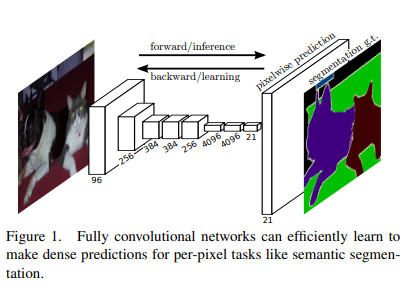
FCN的结构
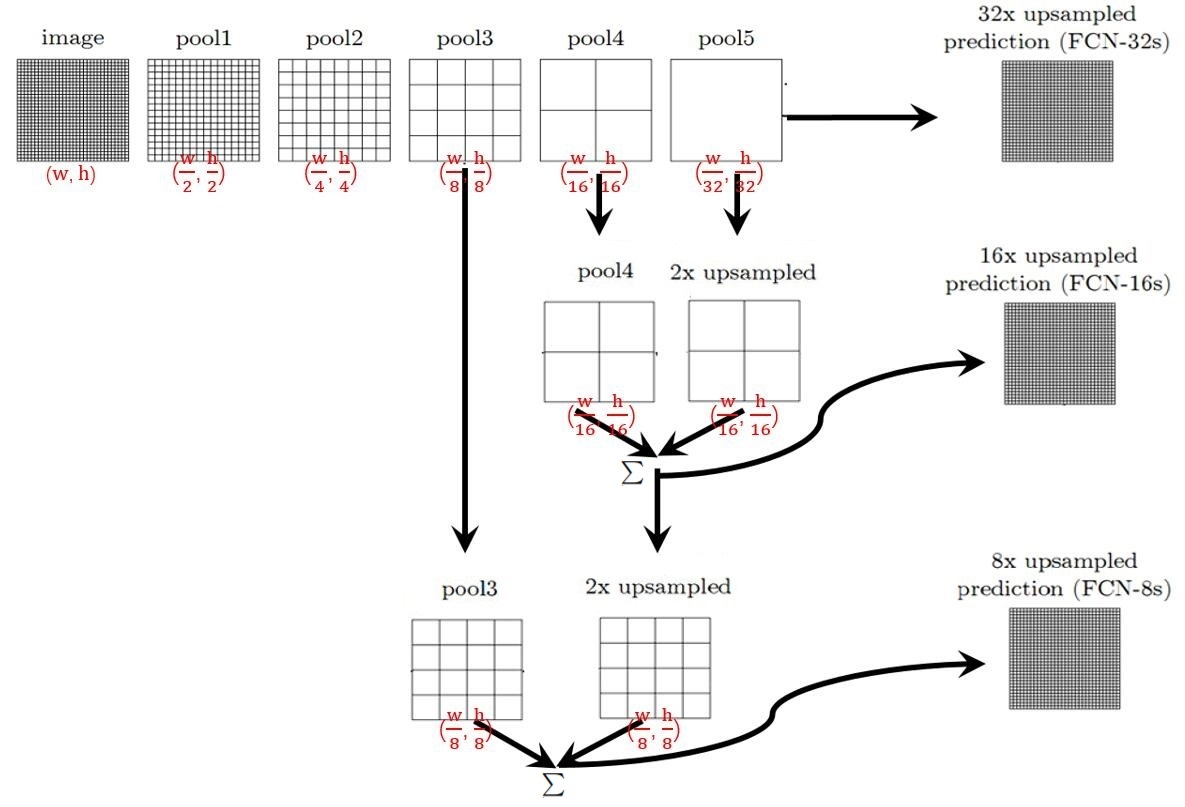
如图所示,一个图片经过conv+max pooling以后,相当于1/2下采样,经过5次下采样以后,在用反卷积进行32倍上采样,再对每个点做softmax计算,就获得了FCN-32s。对第5层的特征图进行2倍上采样,再和第四层的特征图相加,这时对于原图来说相当于16倍下采样,这样在经过16倍上采样并做softmax计算,就得到了FCN-16s。同样,对于FCN8s,就是讲上面的1/16大小的特征图进行下采样,再和第三层的特征图相加,然后再经过一个8倍上采样和softmax计算。
上图这只是一个简单的示例,对于不用的backbone网络,一样是可以按照下采样的位置进行上述操作。