Swin Transformer用MMDET平台进行目标检测的原理
目标检测的Swin Transformer是基于mmdetection的,之前的文章已经分析了mmdetection的原理。
也分析了Swin Transformer用于分类的原理和代码
这篇文章主要讲解Swin Transformer是怎么在mmdetection平台运行的。通过mmdetection的运行机理我们知道,如果要自己建立一个模型,只需要更改几个模型组件backbone、neck、head、roi extractor、loss,并在配置文件中导入即可,另外配置文件也需要写入自己模型的参数、数据集配置、优化器配置、运行配置等。因此我们按照这个思路来看看Swin Transformer是怎么移植到mmdetection平台的。
Swin Transformer Object Detection (STOD)新增的文件
通过对比STOD和原始的MMDET,可以查到STOD新增的文件如下
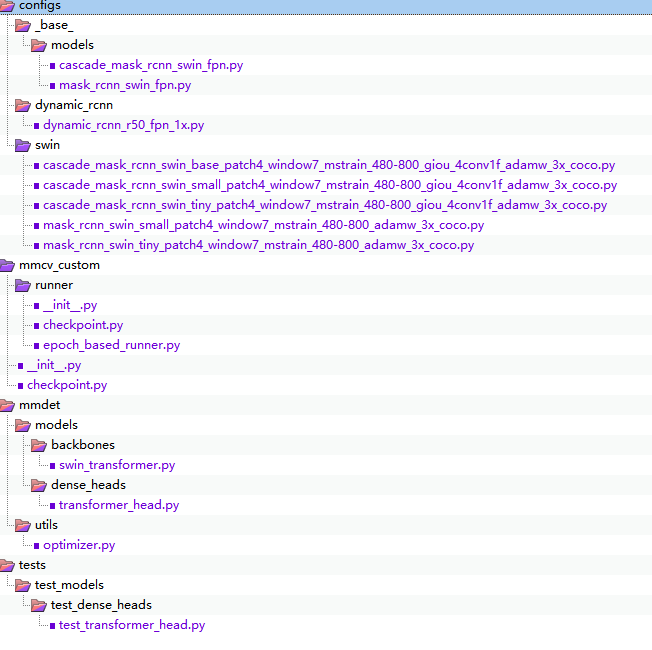
我们分别来看各个部分的差异,分析他们的代码。
1. Models差异
mmdet模型部分的差异如下
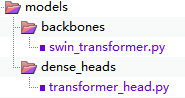
可看见模型部分只有两个文件,但是这里是Swin实现目标检测的核心。首先看backbone,swin_transformer.py实现了Swin算法。
这个文件和原始swin transformer算法的swin_transformer.py文件内容很相似。大部分的类是复制过来的只有部分更改了一下,以适配mmdet。其中没有发生改变的典型类有:window_partition、window_reverse、WindowAttention,它们是SwinTransformerBlock中使用的一些类,实现了窗口分割。窗口注意力计算等功能。
backbone
SwinTransformerBlock
STOD的SwinTransformerBlock类中,输入参数少了input_resolution输入分辨率参数。原始的ST写的更具体,判断了一下输入分辨率和窗口大小的关系,如果窗口更大,就不划分窗口了。此外原始的ST使用掩码来为后续SW-MSA过程准备,但是STOD中没有计算,而是将掩码矩阵放到了forward函数中。
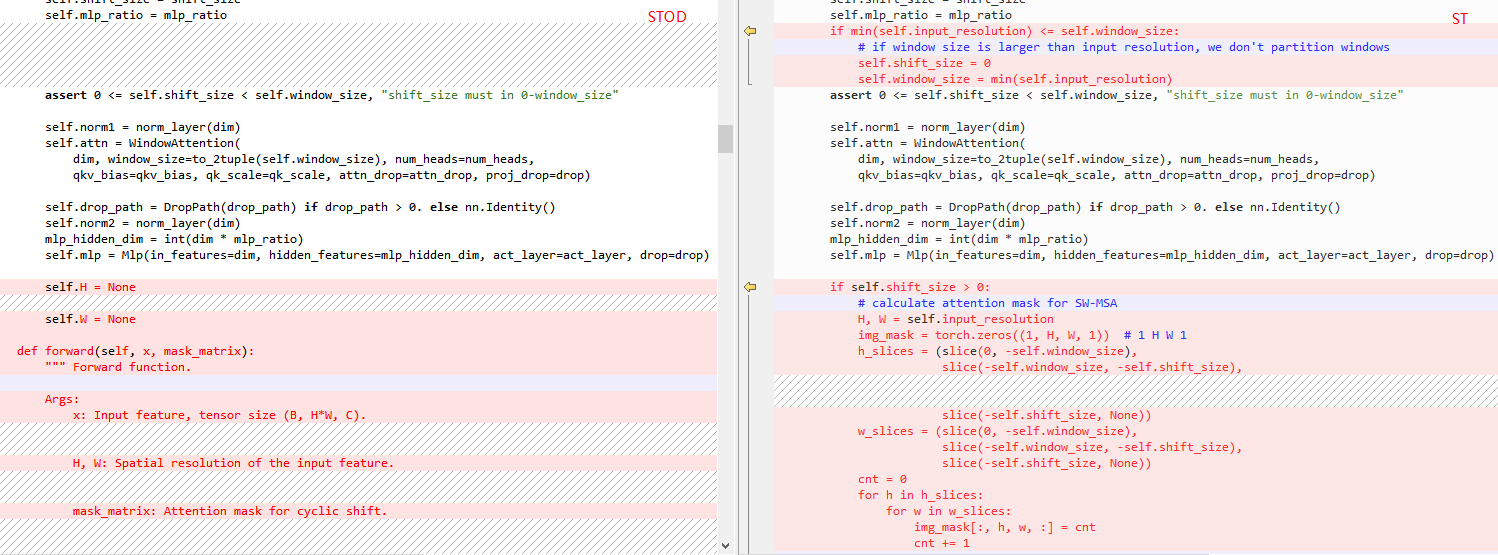
此外,在foward函数中,STOD将特征图填充到了窗口的整数倍大小。
|
|
F.pad是pytorch的填充函数,对三维的x进行填充,这里前后上左的填充值都是0,只对特征图的右和下填充,即针对特征图的右下角填充尺寸。这样计算注意力之后,方便再把特征图改回原尺寸。
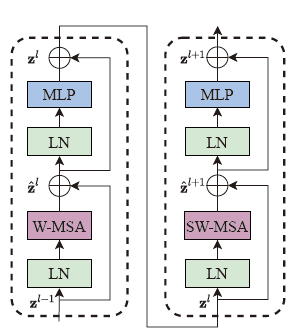
再回顾一下ST Block的基本结构,它由两个基本Transformer组成,一部分标准的多头注意力WMSA+LayerNormal+MLP,一部分移动窗口的SWMSA+LayerNormal+MLP。
这个过程也是在forward函数中进行的。
|
|
计算过程是LayerNormal→循环移位→划分窗口window_partition→多头注意力计算W-MSA/SW-MSA→合并窗口window_reverse→反向循环移位。整个过程和原始的ST完全一样。只不过在循环移位之前先进行了填充,是特征图是window尺寸的倍数,然后在循环移位之后再用x = x[:, :H, :W, :].contiguous()把填充的部分取消。
PatchMerging
PatchMerging是负责下采样的,每一个stage后面都要加一个。它同样变化不大,输入同样少了input_resolution输入分辨率参数,而是在forward中增加了H,W参数,将特征图的H和W直接传过来。
在forward中,同样加入了填充。判断像素点是不是偶数,如果不是就填充一个像素。其余部分没有变化。
|
|
PatchEmbed
PatchEmbed类将输入参数img_size删除了,相关部分的代码也全部删除了。另外,forward中也加入了填充代码。
|
|
BasicLayer
BasicLayer封装了SwinTransformerBlock和下采样在它里面,相当于论文里的一个stage,里面可以设置SwinTransformerBlock深度。BlockSTOD的BasicLayer比ST增加了计算注意力掩码矩阵过程,也就是说在原始ST中在swin Transformer block模块的forward中计算掩码的步骤被移到了BasicLayer的forward方法中,并且计算出掩码矩阵attn_mask。H和W也是直接在forward方法中传递的,建立实例的时候不需要输入参数input_resolution。
SwinTransformer
SwinTransformer是STOD的backbone的主类,它需要对MMDET进行适配,方法就是在代码前面加入@BACKBONES.register_module()修饰器,从而实现在MMDET中注册backbone的作用。这部分也是SwinTransformer作为目标检测的backbone和原始ST分类的主要区别。STOD中加入了冻结参数功能,输入参数中加入frozen_stages参数,它代表冻结哪一个stages。
|
|
其它进行的初始化操作是一样的,首先建立PatchEmbed,然后建立BasicLayer。另外这里还加入了一个对每个stage后面都进行归一化的代码
|
|
out_indices 是mmdet的每个stage索引,是一个元组。这个索引在forward中也用到了。
STOD多了一个train方法,是为了将模型转换为训练模式,同时保持层冻结。
head
STOD的算法中加入了DETR transformer算法的头,但是配置文件中似乎没有使用。它的类名是TransformerHead,所在文件遵循mmdet的规则位于mmdet\models\dense_heads中。DETR文章全称是End-to-End Object Detection with Transformers,下载地址
https://arxiv.org/pdf/2005.12872
|
|
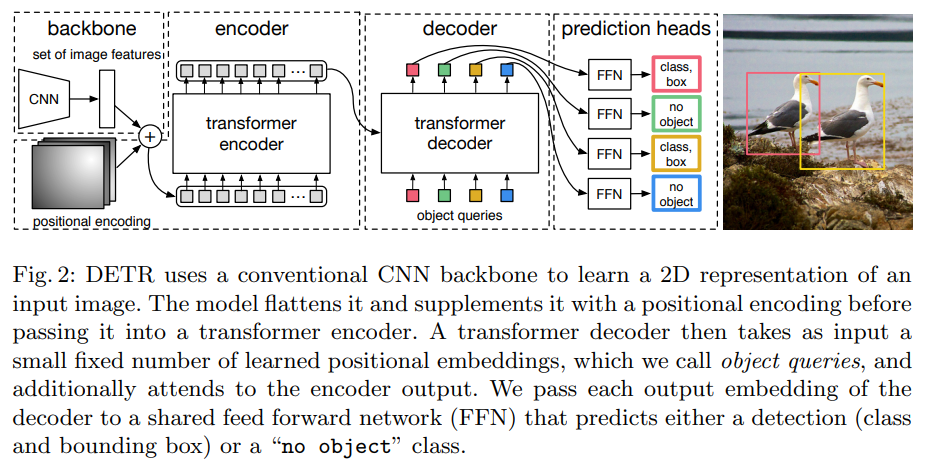
以上是DETR目标检测原理图,图片经过backbone后设置图片特征和位置编码,变成tokens再进入Transformer进行编码和解码(直接用nn.Transformer即可),最后进入FFN预测头。这部分代码就不进行详细解读了,就把它理解为目标检测的头即可。
optimizer
STOD适配MMDT,把优化器放在了mmdet\utils文件夹下,继承OptimizerHook优化器钩子,并注册并导入使其生效。
|
|
2. 配置设置
MMDET的配置中有四个基本组件,models、datasets、schedules和default_runtime,每个完整的配置文件都需要这些配置。STOD增加了models组件的两个基本配置,放在_base_/models文件夹下。其它的datasets、schedules和default_runtime三个组件都没有变化。然后新建了swin文件夹,放置swin的各种配置文件,它们是继承_base_里面的四个基本组件的。
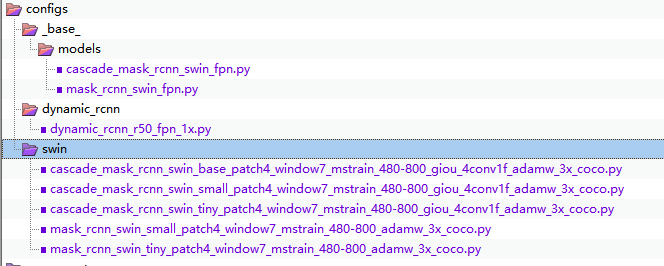
基本组件
首先看一下增加的两个model基本组件的配置文件。cascade_mask_rcnn_swin_fpn.py部分代码如下
|
|
它使用的是CascadeRCNN基本结构,同时backbone的type类型设置了我们之前注册的swin transformer模型,还给出了模型的基本配置,如模型深度、窗口尺寸等等。neck使用的FPN,rpn_head使用的RPNHead,roi_head使用CascadeRoIHead,CascadeRoIHead中使用的配置也都给出。最后还有训练配置和测试配置。
mask_rcnn_swin_fpn.py的基本类型是MaskRCNN,roi_head使用的StandardRoIHead,训练部分的配置也减少了,其它部分基本一样。
完整配置文件
完整配置文件包括四个组件中的所有配置信息,一般是先继承之前的四个基本组件,然后需要更改的在重写进行覆盖。以下是一个完整配置文件的代码。
|
|
可以看到除了继承上面四个基本组件以外,针对不同的模型,可以更改模型的参数,这样对模型进行微调是很方便的。这个模型中,更改了roi_head,加入了其它几个组件的配置。train_pipeline是读取训练数据并预处理用的train=dict(pipeline=train_pipeline),使用的DeTR中的增广策略。除了模型配置,数据集配置,训练配置,还有训练中需要的所有配置都可以放到这个配置文件中。
3. 总结
总体来说Swin Transformer 移植到MMDET上做backbone,改动的地方主要集中在模型的适配,将Swin Transformer类注册到MMDET上,然后根据MMDET的规则去写 配置文件。按照我的理解,模型部分变化主要是因为多目标识别前期会有读取训练数据和数据预处理过程,因此把原模型的很多设置输入分辨率的地方都取消了。而且输入分辨率不知道就要判断一下读取的特征图是不是需要填充。后面的neck和head可以使用任意现有的方法,在MMDET的配置文件中设置即可。或许作者正在开发基于Transformer的类似DERT方法的头,但没有应用在SWIN Transformer上,从github上的修改时间来说,这个头也是一个月内刚修改过,估计不久以后会发出文章。