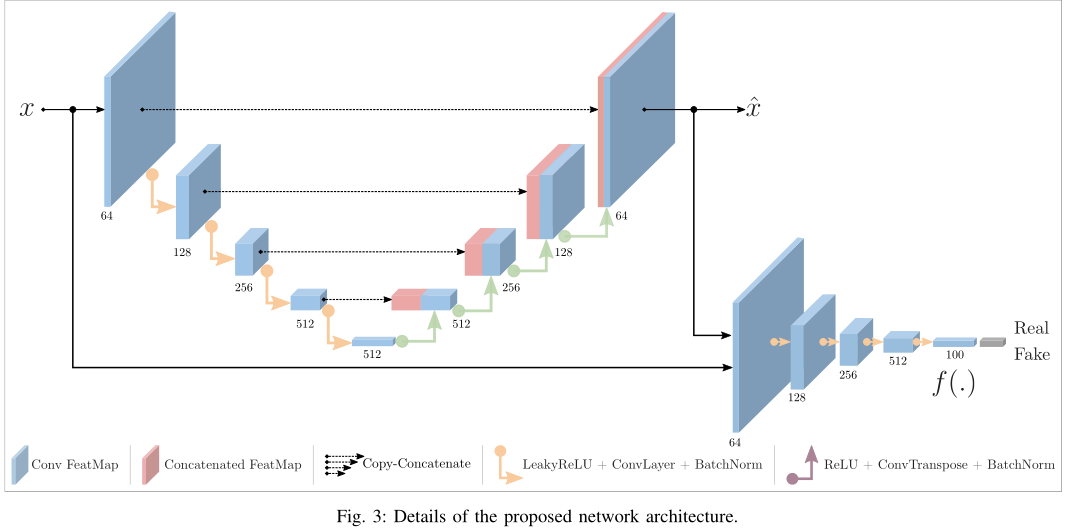
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
|
class Skipganomaly(BaseModel):
"""GANomaly Class
"""
@property
def name(self): return 'skip-ganomaly'
def __init__(self, opt, data=None):
super(Skipganomaly, self).__init__(opt, data)
##
# -- Misc attributes
self.add_noise = True
self.epoch = 0
self.times = []
self.total_steps = 0
##
# Create and initialize networks.
self.netg = define_G(self.opt, norm='batch', use_dropout=False, init_type='normal')
self.netd = define_D(self.opt, norm='batch', use_sigmoid=False, init_type='normal')
##
if self.opt.resume != '':
print("\nLoading pre-trained networks.")
self.opt.iter = torch.load(os.path.join(self.opt.resume, 'netG.pth'))['epoch']
self.netg.load_state_dict(torch.load(os.path.join(self.opt.resume, 'netG.pth'))['state_dict'])
self.netd.load_state_dict(torch.load(os.path.join(self.opt.resume, 'netD.pth'))['state_dict'])
print("\tDone.\n")
if self.opt.verbose:
print(self.netg)
print(self.netd)
##
# Loss Functions
self.l_adv = nn.BCELoss()
self.l_con = nn.L1Loss()
self.l_lat = l2_loss
##
# Initialize input tensors.
self.input = torch.empty(size=(self.opt.batchsize, 3, self.opt.isize, self.opt.isize), dtype=torch.float32, device=self.device)
self.noise = torch.empty(size=(self.opt.batchsize, 3, self.opt.isize, self.opt.isize), dtype=torch.float32, device=self.device)
self.label = torch.empty(size=(self.opt.batchsize,), dtype=torch.float32, device=self.device)
self.gt = torch.empty(size=(opt.batchsize,), dtype=torch.long, device=self.device)
self.fixed_input = torch.empty(size=(self.opt.batchsize, 3, self.opt.isize, self.opt.isize), dtype=torch.float32, device=self.device)
self.real_label = torch.ones (size=(self.opt.batchsize,), dtype=torch.float32, device=self.device)
self.fake_label = torch.zeros(size=(self.opt.batchsize,), dtype=torch.float32, device=self.device)
##
# Setup optimizer
if self.opt.isTrain:
self.netg.train()
self.netd.train()
self.optimizers = []
self.optimizer_d = optim.Adam(self.netd.parameters(), lr=self.opt.lr, betas=(self.opt.beta1, 0.999))
self.optimizer_g = optim.Adam(self.netg.parameters(), lr=self.opt.lr, betas=(self.opt.beta1, 0.999))
self.optimizers.append(self.optimizer_d)
self.optimizers.append(self.optimizer_g)
self.schedulers = [get_scheduler(optimizer, opt) for optimizer in self.optimizers]
def forward(self):
self.forward_g()
self.forward_d()
def forward_g(self):
""" Forward propagate through netG
"""
self.fake = self.netg(self.input + self.noise)
def forward_d(self):
""" Forward propagate through netD
"""
self.pred_real, self.feat_real = self.netd(self.input)
self.pred_fake, self.feat_fake = self.netd(self.fake)
def backward_g(self):
""" Backpropagate netg
"""
self.err_g_adv = self.opt.w_adv * self.l_adv(self.pred_fake, self.real_label)
self.err_g_con = self.opt.w_con * self.l_con(self.fake, self.input)
self.err_g_lat = self.opt.w_lat * self.l_lat(self.feat_fake, self.feat_real)
self.err_g = self.err_g_adv + self.err_g_con + self.err_g_lat
self.err_g.backward(retain_graph=True)
def backward_d(self):
# Fake
pred_fake, _ = self.netd(self.fake.detach())
self.err_d_fake = self.l_adv(pred_fake, self.fake_label)
# Real
# pred_real, feat_real = self.netd(self.input)
self.err_d_real = self.l_adv(self.pred_real, self.real_label)
# Combine losses.
self.err_d = self.err_d_real + self.err_d_fake + self.err_g_lat
self.err_d.backward(retain_graph=True)
def update_netg(self):
""" Update Generator Network.
"""
self.optimizer_g.zero_grad()
self.backward_g()
self.optimizer_g.step()
def update_netd(self):
""" Update Discriminator Network.
"""
self.optimizer_d.zero_grad()
self.backward_d()
self.optimizer_d.step()
if self.err_d < 1e-5: self.reinit_d()
##
def optimize_params(self):
""" Optimize netD and netG networks.
"""
self.forward()
self.update_netg()
self.update_netd()
##
def test(self, plot_hist=False):
""" Test GANomaly model.
Args:
data ([type]): Dataloader for the test set
Raises:
IOError: Model weights not found.
"""
with torch.no_grad():
# Load the weights of netg and netd.
if self.opt.load_weights:
self.load_weights(is_best=True)
self.opt.phase = 'test'
scores = {}
# Create big error tensor for the test set.
self.an_scores = torch.zeros(size=(len(self.data.valid.dataset),), dtype=torch.float32, device=self.device)
self.gt_labels = torch.zeros(size=(len(self.data.valid.dataset),), dtype=torch.long, device=self.device)
self.features = torch.zeros(size=(len(self.data.valid.dataset), self.opt.nz), dtype=torch.float32, device=self.device)
print(" Testing %s" % self.name)
self.times = []
self.total_steps = 0
epoch_iter = 0
for i, data in enumerate(self.data.valid, 0):
self.total_steps += self.opt.batchsize
epoch_iter += self.opt.batchsize
time_i = time.time()
# Forward - Pass
self.set_input(data)
self.fake = self.netg(self.input)
_, self.feat_real = self.netd(self.input)
_, self.feat_fake = self.netd(self.fake)
# Calculate the anomaly score.
si = self.input.size()
sz = self.feat_real.size()
rec = (self.input - self.fake).view(si[0], si[1] * si[2] * si[3])
lat = (self.feat_real - self.feat_fake).view(sz[0], sz[1] * sz[2] * sz[3])
rec = torch.mean(torch.pow(rec, 2), dim=1)
lat = torch.mean(torch.pow(lat, 2), dim=1)
error = 0.9*rec + 0.1*lat
time_o = time.time()
self.an_scores[i*self.opt.batchsize: i*self.opt.batchsize + error.size(0)] = error.reshape(error.size(0))
self.gt_labels[i*self.opt.batchsize: i*self.opt.batchsize + error.size(0)] = self.gt.reshape(error.size(0))
self.times.append(time_o - time_i)
# Save test images.
if self.opt.save_test_images:
dst = os.path.join(self.opt.outf, self.opt.name, 'test', 'images')
if not os.path.isdir(dst): os.makedirs(dst)
real, fake, _ = self.get_current_images()
vutils.save_image(real, '%s/real_%03d.eps' % (dst, i+1), normalize=True)
vutils.save_image(fake, '%s/fake_%03d.eps' % (dst, i+1), normalize=True)
# Measure inference time.
self.times = np.array(self.times)
self.times = np.mean(self.times[:100] * 1000)
# Scale error vector between [0, 1]
self.an_scores = (self.an_scores - torch.min(self.an_scores)) / \
(torch.max(self.an_scores) - torch.min(self.an_scores))
auc = roc(self.gt_labels, self.an_scores)
performance = OrderedDict([('Avg Run Time (ms/batch)', self.times), ('AUC', auc)])
##
# PLOT HISTOGRAM
if plot_hist:
plt.ion()
# Create data frame for scores and labels.
scores['scores'] = self.an_scores
scores['labels'] = self.gt_labels
hist = pd.DataFrame.from_dict(scores)
hist.to_csv("histogram.csv")
# Filter normal and abnormal scores.
abn_scr = hist.loc[hist.labels == 1]['scores']
nrm_scr = hist.loc[hist.labels == 0]['scores']
# Create figure and plot the distribution.
# fig, ax = plt.subplots(figsize=(4,4));
sns.distplot(nrm_scr, label=r'Normal Scores')
sns.distplot(abn_scr, label=r'Abnormal Scores')
plt.legend()
plt.yticks([])
plt.xlabel(r'Anomaly Scores')
##
# PLOT PERFORMANCE
if self.opt.display_id > 0 and self.opt.phase == 'test':
counter_ratio = float(epoch_iter) / len(self.data.valid.dataset)
self.visualizer.plot_performance(self.epoch, counter_ratio, performance)
##
# RETURN
return performance
|