Swin Transformer代码详解
源代码地址:[https://github.com/microsoft/Swin-Transformer]
Swin Transformer 代码结构
|
|
Swin Transformer执行文件是main.py,它包含了几个基本的函数:
程序入口是main,调用其它函数。Main中最关键的是这两个对象的建立
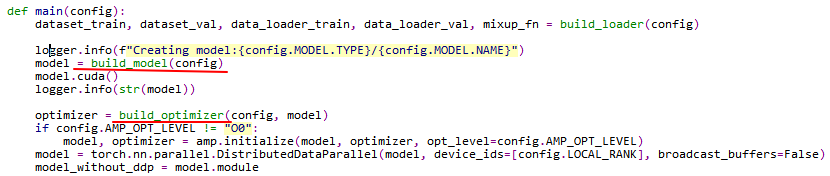
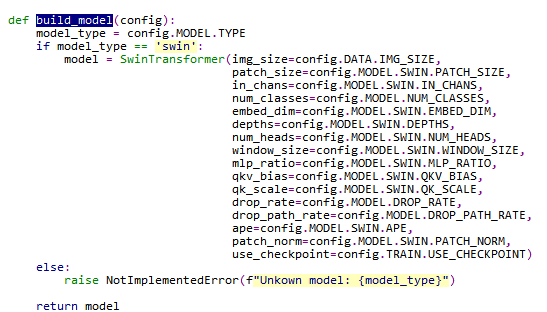
build_model
build_model位于/models/build.py文件内,build_optimizer位于optimizer.py文件内。首先先分析build_model,它的内容只是继承了一下SwinTransformer类。
SwinTransformer类位于Swin_transformer.py中,它包含了模型建立阶段的所有操作,包括将图像拆分为Patchs并内嵌embedding、建立Swin Transformer block模块等等。Swin_transformer.py文件包含这些类和函数:
SwinTransformer
SwinTransformer类调用了其它几个类和函数,实现了算法建模的主要功能。

首先先看图像的拆分和embedding:

它实现了图像嵌入PatchEmbed类的实例,这个对象定义了图片大小,patch大小,嵌入维度标准化层等等参数。而PatchEmbed类继承了pytorch的nn.Module,里面只有两个关键方法,forward和flops。
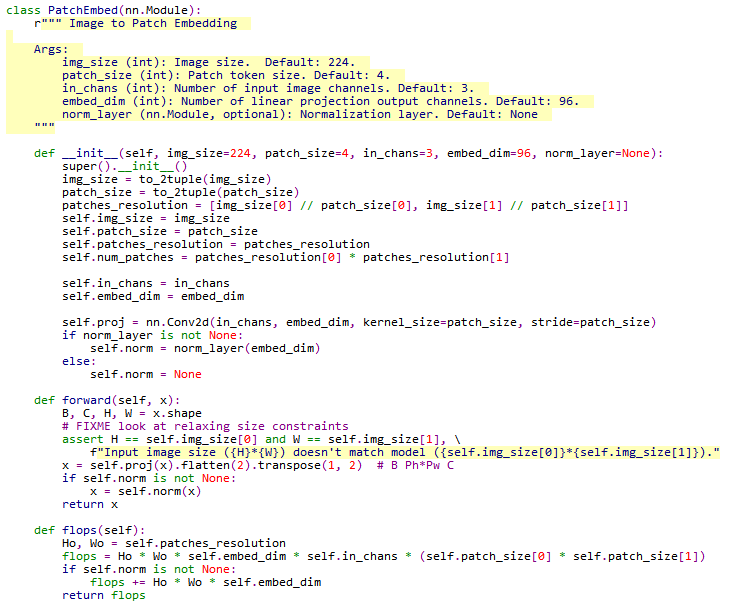
forward是重新实现的nn.Module方法,它描述了模块内对张量(BCHW型的)进行的操作。
重点是这一行
|
|
其中self.proj是在__init__中定义的
|
|
就是用nn.Conv2d实现的逐个patch乘以相应大小的卷积核,并且步长Stride也是batch尺寸。这样就实现了每个卷积核只对每个patch线性映射一次的效果。输出通道数即为卷积核的个数。

卷积操作(线性映射)以后,还需要对其进行压平处理。x.flatten(2).transpose(1, 2)的效果如图
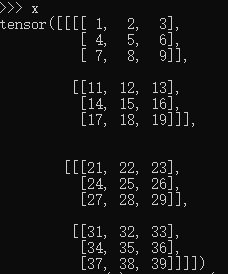
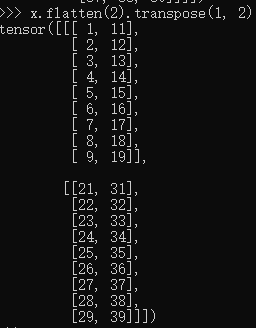
意思是将原本(B,C,H,W)维度的tensor转化为(B,H*W,C),即将2维的特征压平成1维的。
Flops是算浮点运算次数的方法,可以先不看。
然后一起学习一下SwinTransformer类实现的其它功能。
随机深度stochastic depth。这部分的代码是
|
|
借鉴的文章是Deep Networks with Stochastic Depth(https://arxiv.org/pdf/1603.09382)))。原理后面再说。
下面是建立层
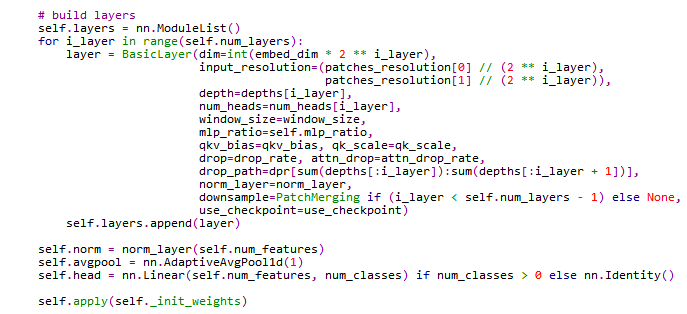
代码中建了一个nn.ModuleList,它可以像python的list一样被索引,所以也可以append。这样就可以做一个循环,然后把所有层都放到self.layer中。根据层数不同,每次循环改变维数。这部分功能主要用到了一个BasicLayer类,它和SwinTransformer类在同一文件中,同样继承的nn.Module。
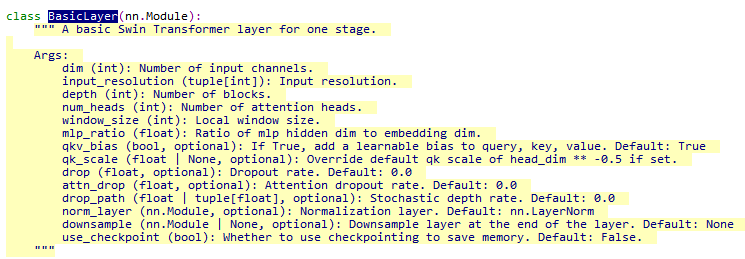
这个BasicLayer类里面,建立了self.block,是用SwinTransformerBlock建的。
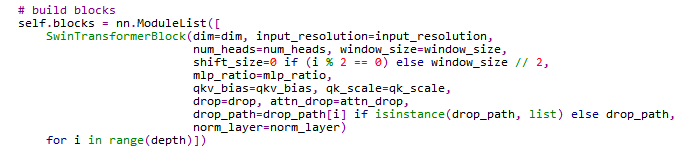
SwinTransformerBlock
SwinTransformerBlock是文章内容的核心之一,它的主要功能是进行窗口分割、改变Patch的尺寸、窗口shift后进行填充、计算多头注意力。
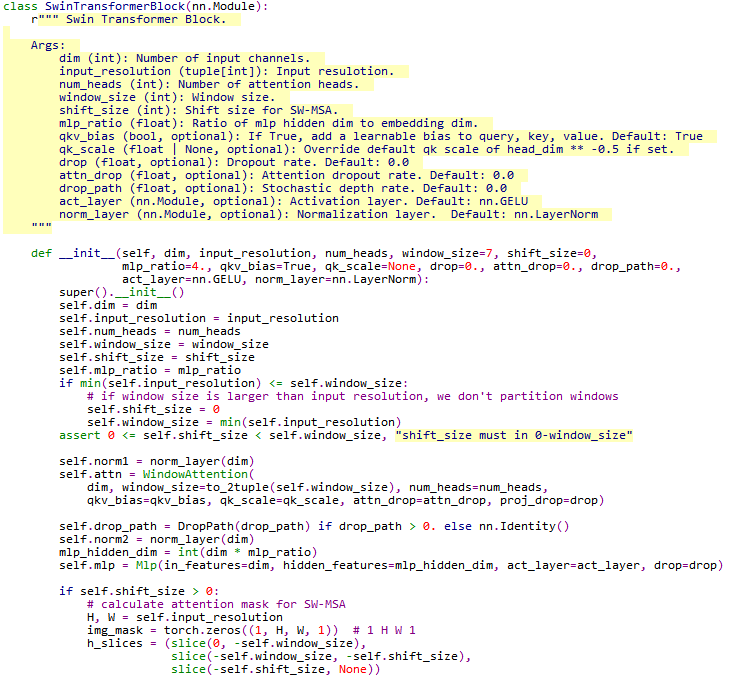
先是self.norm1标准化层,然后是self.attn计算注意力,然后再是标准化层self.norm2,然后是多层感知器self.mlp。后面定义了切割窗口时如果需要填充,标记了注意力掩码attn_mask,方便后面计算注意力的时候只计算自己相关的窗口,而不计算位移填充到一起的不相关的窗口。
重新构建的forward函数,包括循环填充、划分窗口、W-MSA/SW-MSA、去掉多余窗口以及前向短路FFN。

在__init__中定义了self.attn计算注意力,构建了一个WindowAttention的对象。这部分是ViT方法的核心,计算了窗口的注意力。
WindowAttention
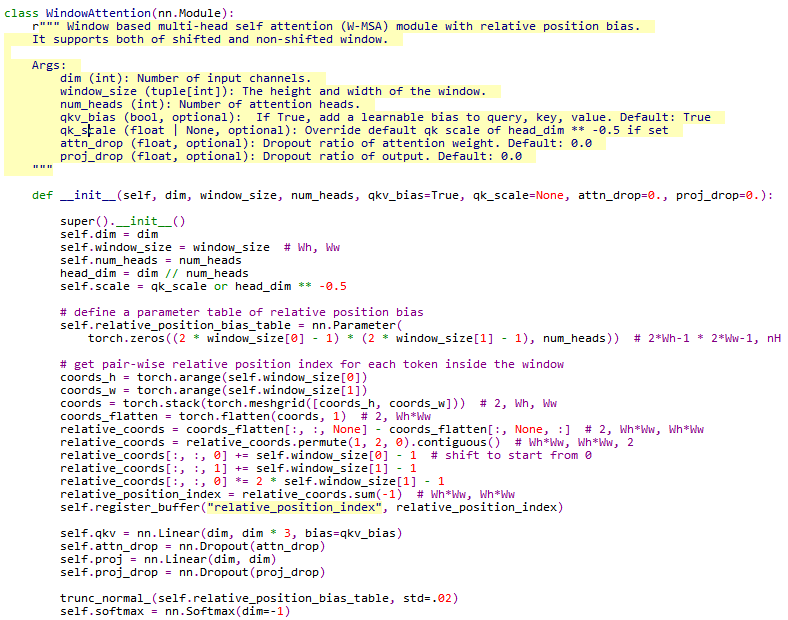
计算多头注意力的过程是先建立了相对位置的偏差表
|
|
然后计算了窗口内每个tokens的成对相对位置索引relative_position_index。# 窗口WhWw, WhWw
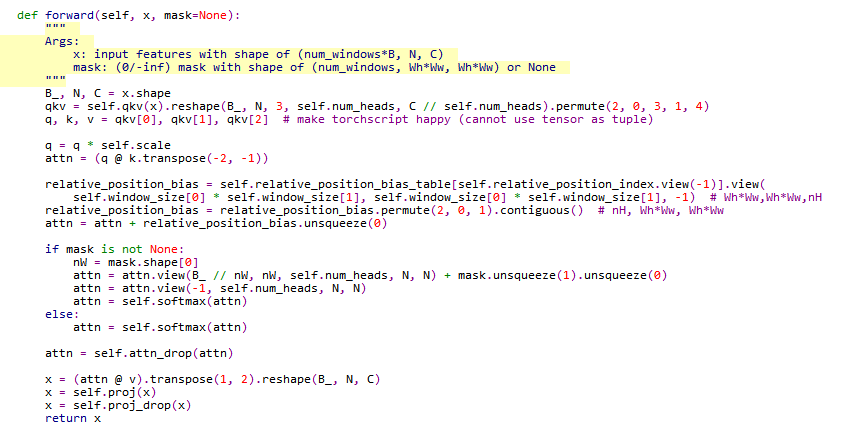
重新构建的forward函数进行了注意力计算。首先计算query、key、value三个参数。
|
|
然后计算注意力
$$\begin{equation} \operatorname{Attention}(Q, K, V)=\operatorname{SoftMax}\left(Q K^{T} / \sqrt{d}+B\right) V \end{equation}$$
|
|